The Archer and Perplexity: Diving into LLM evaluation metrics — The measure of perplexity

LLMs are everywhere — They are only going to get larger from here. The efficiency, the potential, and the possibilities are infinite. I know it, you know it, and so do all the Silicon Valley and almost every other tech startup. But with this new technology comes new terms, new ways to evaluate, and new numbers to calculate.
I am looking to explore and simplify the metrics that we can use to evaluate any LLM as we build new projects, agents, workflows….. and infinite other things.
Let’s start from the beginning.
The metrics for language modelling and much of the data science that we do are rooted in a lot of different statistical theories. As we look back, theories and formulae from the 1950s were foundational in a lot of stuff that we do that. One of such was the metric Perplexity, which is rooted in information theory and early statistical language modelling. It has not been tied (as far as I know) to a specific publication, but has been a part of language modelling since its inception in the 1990s.
With perplexity, we intend to measure the element of surprise the LLM had in predicting the word. At first glance, perplexity seems like a measure of confidence. However, it is a measure of how confident the model is in predicting the correct word. It goes beyond simple word-by-word comparisons, which miss deeper understanding, by evaluating how well the model predicts what’s actually correct — and how confidently it does so.
It is only fitting that the performance tests of LLMs would start with this metric, and it only gets better from here.
Before we dive into the mathematics, I want to take the analogy of our archer friend. Let's call him Archy. We want to analyze Archy, based on his ability to perform well by hitting the bullseye, but also doing that in different scenarios — rain, pressure, heat, winter, and so on. So we devise a system that:
- If Archy is confident and misses the bullseye- that is bad.
- If Archy shoots confidently and hits the bullseye, great! +10 points.
- If they are unsure and weakly shoot near bullseye- that is meh.
Perplexity evaluates both:
Did you shoot toward the right spot? (Was your prediction aligned with the truth?)
And how confident were you in that shot?
So perplexity is like asking:
“How surprised were you to see the correct word?”
Less surprise = better model.
Mathematically speaking, we calculate the model’s probability of the correct word at each step, take the log (since probabilities are between 0 and 1), average them, then exponentiate the negative of that average to get the final perplexity.
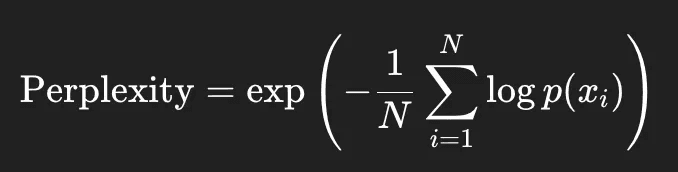
The negative sign helps counteract the fact that the logs of probabilities are negative.
Now let's say the model correctly predicts all the words — then the logarithm of each word would be essentially zero, which then makes the exponent zero, and Perplexity would be 1. Which means that the model is super confident and super precise — GO ARCHY!!!!
But any other uncertainty is going to change the exponent to a value greater than 0, and thus Perplexity greater than one. So for a perplexity of say 1.39, as if the model is choosing between 1.39 equally likely options at each step. Fascinating measure of surprise (reminds me of entropy a bit.)
Pretty straightforward, right?
However, this simplicity comes with limitedness on diversity, and thus the insufficiency of Perplexity as a holistic metric.
Perplexity is a powerful metric for measuring a language model’s ability to predict the exact next token, but it falls short when language generation is more creative or ambiguous. It cannot reward a model for producing different yet valid continuations, nor can it assess whether the output makes sense semantically or factually. As such, perplexity is often inadequate for evaluating tasks like summarization, dialogue, or open-ended generation, where diversity and meaning matter more than token-level accuracy.
Well, we did measure how Archy performed, and he is taking it slow, as he learned about his latest assessment. But right now, this is the end of the article. I am hoping to dive more into other metrics to evaluate LLMs, and hopefully give a detailed approach to when to choose which one, but if you want a grounded starting point for how confident your LLM is in predicting the next word — perplexity is where your journey begins.